一、NGCF [2019]
《Neural Graph Collaborative Filtering》
个性化推荐无处不在,已广泛应用于电商、广告、社交媒体等众多在线服务。个性化推荐的核心是根据购买和点击等历史交互(
historical interaction)来估计用户接受某个item的可能性。协同过滤(
collaborative filtering: CF)通过假设行为相似的用户对item表现出相似的偏好来解决这个问题。为了实现这个假设,一个常见的范式(paradigm)是参数化(parameterize)用户和item以重建历史交互,并根据参数(parameter)来预估用户偏好。一般而言,可学习的
CF模型有两个关键组件(key component):embedding:将用户和item转换为向量化的representation。交互建模:基于
embedding重建历史交互。
例如:
矩阵分解(
matrix factorization: MF)直接将user id / item id映射到embedding向量,并使用内积对user-item交互进行建模。协同深度学习(
collaborative deep learning)通过整合从item的丰富的辅助信息(side information)中学到的deep representation来扩展MF embedding function。神经协同过滤模型(
neural collaborative filtering model)用非线性神经网络代替MF的内积交互函数。translation-based CF model使用欧氏距离作为交互函数。
尽管这些方法很有效,但是我们认为它们不足以为
CF产生令人满意的embedding。关键原因是embedding函数缺乏关键协同信号(collaborative signal)的显式编码,这种编码隐藏在user-item交互中从而揭示用户(或item)之间的行为相似性。更具体而言,大多数现有方法仅使用描述性特征(例如ID和属性)来构建embedding函数,而没有考虑user-item交互。因此,由此产生的embedding可能不足以捕获协同过滤效果(effect)。user-item交互仅用于定义模型训练的目标函数。因此,当embedding不足以捕获CF时,这些方法必须依靠交互函数来弥补次优(suboptimal)的embedding的不足。虽然将
user-item交互集成到embedding函数中在直观上很有用,但是要做好并非易事。特别是在实际应用中,user-item交互的规模很容易达到数百万甚至更大,这使得提取所需要的的协同信号变得困难。在论文《Neural Graph Collaborative Filtering》中,作者通过利用来自user-item交互的高阶连通性(high-order connectivity)来应对这一挑战,这是一种在交互图结构(interaction graph structure)中编码协同信号的自然方式。下图说明了高阶连通性的概念。待推荐的用户是
user-item交互图的左子图中用双圆圈来标记。右子图显示了从路径
item更长的路径
item此外,从
itemitem
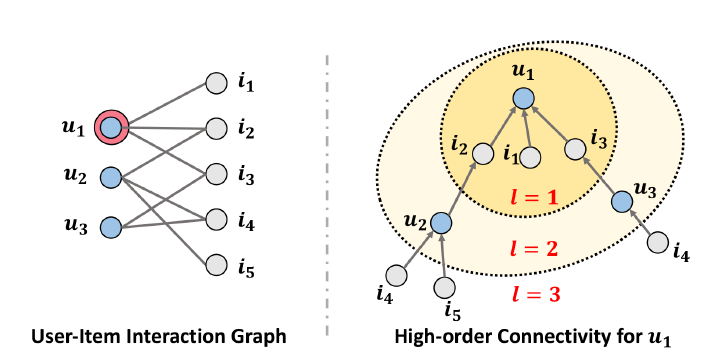
论文提出对
embedding函数中的高阶连通性信息进行建模。论文没有将交互图扩展为实现起来很复杂的树,而是设计了一种神经网络方法在图上递归地传播embedding。这是受到图神经网络最近发展的启发,可以将其视为在embedding空间中构建信息流(information flow)。具体而言,作者设计了一个embedding propagation layer,它通过聚合交互的item(或者user)的embedding来改进refine用户(或者item)的embedding。通过堆叠多个embedding propagation layer,模型可以显式强制embedding来捕获高阶连通性中的协同信号。以上图为例,堆叠两层可以捕获论文在三个公共
benchmark上进行了广泛的实验,验证了神经图协同过滤(Neural Graph Collaborative Filtering: NGCF)方法的合理性和有效性。最后值得一提的是,尽管在最近的一种名叫
HOP-Rec的方法中已经考虑了高阶连通性信息,但是它仅用于丰富训练数据。具体而言,HOPRec的预测模型仍然是MF,而且它是通过优化用高阶连通性增强的损失函数来训练的。和HOP-Rec不同,NGCF贡献了一种新技术将高阶连通性集成到预测模型中,从经验上讲,它比HOP-Rec更好地嵌入CF。总而言之,论文的主要贡献:
论文强调在基于模型的
CF方法的embedding函数中利用协同信号的重要性。论文提出了
NGCF,这是一种基于图神经网络的新推荐框架,它通过执行embedding传播,以高阶连通性的形式对协同信号进行显式编码。论文对三个百万规模的数据集进行实证研究。大量结果证明了
NGCF的SOTA性能,以及通过神经embedding传播来提高embedding质量方面的有效性。
论文回顾了现有的
model-based CF、graph-based CF、基于图神经网络的方法的现有工作,这些方法和本文的工作最为相关。这里,论文强调这些方法和NGCF的不同之处。Model-Based CF方法:现代推荐系统通过向量化表示(vectorized representation)来参数化(parameterize)用户和item,并基于模型参数重建user-item交互数据。例如,MF将每个user ID和item ID投影为embedding向量,并在它们之间进行内积以预测交互。为了增强embedding函数,已经付出了很多努力来融合诸如item content、社交关系、item关系、用户评论、外部知识图谱等辅助信息(side information)。虽然内积可以迫使观察到的、交互的
user embedding和item embedding彼此接近,但是其线性不足以揭示用户和item之间复杂的非线性关系。为此,最近的努力侧重于利用深度学习技术来增强交互函数,从而捕获用户和item之间的非线性特征交互。例如,神经协同模型(如NeuMF)采用非线性神经网络作为交互函数。同时,基于翻译的CF模型,例如LRML用欧氏距离来建模交互强度(interaction strength)。尽管取得了巨大的成功,但我们认为
embedding函数的设计不足以为协同过滤产生最佳的embedding,因为协同过滤信号只能被隐式(implicitly)地捕获。总结这些方法,embedding函数将描述性特征(descriptive feature)(如ID特征和属性特征)转换为向量,而交互函数作为向量上的相似性度量。理想情况下,当user-item交互被完美重建时,行为相似性的传递特性(transitivity property)可以被捕获。然而,前面示例(高阶连通性概念的示例)中显示的这种传递效应(transitivity effect)并没有被显式地编码,因此无法保证间接连接的用户和item在embedding空间中也是接近的。如果没有对协同信号进行显式编码,就很难获得满足所有特性的embedding。即,传统的方法仅优化了
user-item的一阶邻近性,并没有优化高阶邻近性。另外这种邻近性并不是在模型结构中显式编码的,而是通过目标函数来优化的。Graph-Based CF方法:另一个研究方向利用user-item interaction graph来推断用户偏好。早期的努力,如
ItemRank和BiRank采用标签传播的思想来捕获协同效应(CF effect)。为了给一个用户在所有item上打分,这些方法将用户历史交互的item打上label,然后在图上传播标签。由于推荐分是基于历史互动item和目标item之间的结构可达性(structural reachness)(可以视为一种相似性)而获得的,因此这些方法本质上属于基于邻域(neighbor-based)的方法。然而,这些方法在概念上不如基于模型的协同过滤方法,因为它们缺乏模型参数来优化推荐目标函数(既没有模型参数、又没有目标函数、更没有优化过程)。最近提出的
HOP-Rec方法通过将基于图的方法和基于embedding的方法相结合来缓解这个问题(缺乏模型参数来优化推荐目标函数的问题)。该方法首先执行随机游走以丰富用户和multi-hop连接的item之间的交互。然后它基于丰富的user-item交互数据(通过高阶连通性增强的正样本)训练具有BPR目标函数的MF从而构建推荐模型。HOP-Rec优于MF的性能证明,结合连通性信息有利于在捕获CF效应时获得更好的embedding。然而,我们认为HOP-Rec没有充分探索高阶连通性,它仅仅用于丰富训练数据,而不是直接有助于模型的embedding函数(因为推断时不会用到正样本增强技术,而是用到embedding函数)。此外,HOP-Rec的性能在很大程度上取决于随机游走,这需要仔细地调优,例如设置合适的衰减因子。图卷积网络(
Graph Convolutional Network):通过在user-item交互图上设计专门的图卷积运算,我们使NGCF有效地利用高阶连通性中的CF信号。这里我们讨论现有的、也采用图卷积运算的方法。GC-MC在user-item交互图上应用了图卷积网络(graph convolution network: GCN),但是它仅使用一个卷积层来利用user-item之间的直接连接。因此,它无法揭示高阶连通性中的协同信号。PinSage是一个工业解决方案,它在item-item图中采用了多个图卷积层从而进行Pinterest图像推荐。因此,CF效应是在item关系的层面上捕获的,而不是在集体(collective)的用户行为的层面上。Spectral CF提出了一种谱卷积操作来发现谱域中用户和item之间的所有可能的连接。通过图邻接矩阵的特征分解,可以发现user-item pair对之间的连接。然而,特征分解导致了很高的计算复杂度,非常耗时并且难以支持大规模的推荐场景。
1.1 模型
NGCF模型的架构如下图所示(给出了用户itemaffinity score),其中包含三个组件(components):一个
embedding层:提供user embedding和item embedding。多个
embedding传播层:通过注入高阶连通性关系来refine embedding。一个
prediction层: 聚合来自不同传播层的refined embedding并输出user-item的相似性得分(affinity score)。
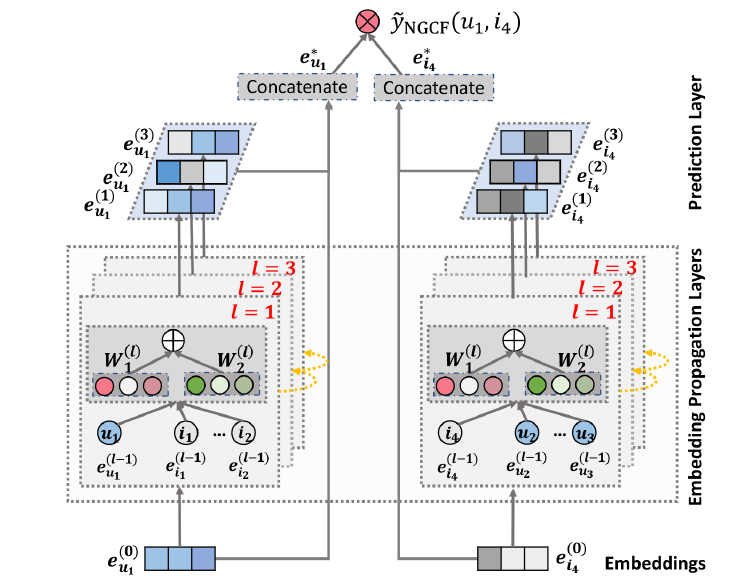
1.1.1 Embedding Layer
遵循主流推荐模型,我们用
embedding向量embedding向量itemembedding维度。这可以看做是将参数矩阵(parameter matrix)构建为embedding look-up table:其中
item数量。值得注意的是,这个
embedding table作为user embedding和item embedding的初始状态(refine之前的状态),并以端到端的方式进行优化。在传统的推荐模型如
MF和神经协同过滤中,这些ID embedding直接输入一个交互层(interaction layer)来实现分数预估。相比之下,在我们的
NGCF框架中,我们通过在user-item交互图上传播embedding来refine embedding。这导致了对推荐更有效的embedding,因为embedding的refinement步骤显式地将协同信号注入到embedding中。
1.1.2 Embedding Propagation
接下来我们基于
GNN的消息传递框架,沿着图结构捕获协同信号并优化user embedding和item embedding。我们首先说明单层embedding传播层(Embedding Propagation Layer)的设计,然后将其推广到多个连续传播层。一阶传播
First-order Propagation:直观地,交互的item提供了关于用户偏好的直接证据。类似地,消耗一个item的用户可以被视为item的特征,并用于度量两个item的协同相似性(collaborative similarity)。我们在此基础上在连接(connected)的用户和item之间执行embedding传播,用两个主要操作来形式化(formulating)流程:消息构建(message construction)和消息聚合(message aggregation)。消息构建:对一个连接的
user-item pair对其中:
message embedding。message encoding函数,函数的输入为item embeddinguser embedding系数
edgedecay factor)。
在本文中,我们定义
其中:
item数量),item
与仅考虑
graph convolution network)不同,这里我们额外将affinity),例如从相似的item传递更多消息。这不仅提高了模型的表示能力(representation ability),还提高了推荐性能。遵循图卷积网络,我们将
graph Laplacian norm)item从
representation learning的角度来看,item对用户偏好的贡献程度。从消息传递的角度来看,考虑到被传播的消息应该随着路径长度(
path length)衰减,discount factor)。消息聚合:在这一阶段,我们聚合从用户
refine用户representation。具体而言,我们定义聚合函数为:其中:
embedding传播层之后获得的用户representation。LeakyReLU激活函数允许消息对正(positive)信号和小负(negative)信号进行编码。除了从邻域
self-connection):这个自连接保留了
注意:这里的
类似地,我们可以通过与
item连接的用户传播的消息来获得itemrepresentation总而言之,
embedding传播层的优势在于显式利用一阶连通性信息来关联user representation和item representation。在广告和推荐场景中,
itemitemitem集合)通常都比较小。如何处理这种非对称的、庞大的邻域是一个难点。高阶传播(
High-order Propagation):基于一阶连通性(first-order connectivity)建模来增强representation,我们可以堆叠更多embedding传播层来探索高阶连通性(high-order connectivity)信息。这种高阶连通性对于编码协同信号以估计用户和item之间的相关性分数(relevance score)至关重要。通过堆叠embedding传播层,用户(或者item)能够接收来自L-hop邻居传播的消息。在第
representation被递归地表示为:其中被传播的消息定义为:
其中:
注意:这里对于
item representation,它记住了(l-1) - hop邻域的消息。user representation,它也也记住了(l-1) - hop邻域的消息。
类似地,我们也可以得到
itemrepresentation。如下图所示为针对用户
embedding传播,像embedding传播过程中捕获。即,来自embedding传播层无缝地将协同信号注入到representation learning过程。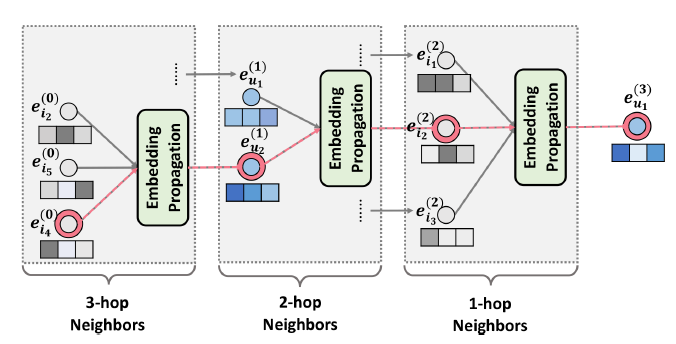
矩阵形式的传播规则(
Propagation Rule in Matrix Form):为了提供embedding传播的整体视图(holistic view),并便于batch实现,我们提供了layer-wise传播规则的矩阵形式:其中:
embedding传播层得到的用户representation和item representation。representation,即user-item graph的拉普拉斯矩阵:其中
user-item交互矩阵,degree matrix)(因此
它就是
通过实现矩阵形式的传播规则,我们可以用一种相当有效的方式同时更新所有用户和所有
item的representation。这种方式允许我们抛弃节点采样过程(这个节点采样过程通常用于图卷积网络,使得图卷积网络可以应用于大规模的graph)。对于工业场景海量用户(如十亿级)和海量
item(如亿级),那么矩阵形式是不可行的,因为现有的计算资源无法处理如此规模的矩阵。
1.1.3 Model Prediction
经过
representation,即representation强调通过不同连通性传递的消息,因此它们在反映用户偏好方面有不同的贡献。因此,我们将这些representation拼接起来,构成用户representation。对于
itemitem representaitonitemrepresentation。最终我们得到user representation和item representation为:其中
||表示向量拼接。通过这种方式,我们不仅用
embedding传播层丰富了initial embeddings(即embedding层得到的初始embedding),还允许通过调整注意,除了拼接之外,还可以应用其它聚合方式,如加权平均、最大池化、
LSTM等,这意味着在组合不同阶次的连通性时有不同的假设。使用拼接聚合的优势在于它的简单性,因为它不需要学习额外的参数,并且它已经在最近的图神经网络中证明非常有效。最后,我们使用内积来估计用户
item在这项工作中,我们强调
embedding函数的学习,因此仅使用内积这种简单的交互函数。其它更复杂的选择,如基于神经网络的交互函数,留待未来的研究工作。
1.1.4 Optimization
为了学习模型参数,我们优化了在推荐系统中广泛应用的
pairwise BPR loss。该损失函数考虑了观察到的和未观察到的user-item交互之间的相对顺序。具体而言,
BPR假设观察到的user-item交互更能够反映用户的偏好,因此应该比未观察到的交互分配更高的预测值。因此目标函数为:其中:
pairwise训练数据。sigmoid函数。L2正则化系数。
我们使用
mini-batch的Adam优化算法来优化预估模型。具体而言,对于一个batch的随机采样的三元组L步传播之后建立它们的representation模型大小(
Model Size):值得指出的是,尽管NGCF在每个传播层embedding矩阵embedding矩阵来自于embedding look-up tableuser-item图结构和权重矩阵转换而来。因此,和最简单的、基于
embedding的推荐模型MF相比,我们的NGCF只是多了5的数,并且embedding size(远小于用户数量和item数量),因此这个额外的参数规模几乎可以忽略不计。例如,在我们实验的
Gowalla数据集(20k用户和40k item)上,当embedding size = 64并且我们使用3个尺寸为64 x 64的传播层时,MF有450万参数,而我们的NGCF仅使用了2.4万额外的参数。总之,
NGCF使用很少的额外参数来实现高阶连通性建模。Message and Node Dropout:虽然深度学习模型具有很强的表示能力,但通常会出现过拟合现象。Dropout是防止神经网络过拟合的有效解决方案。遵从图卷积网络的前期工作,我们提出在NGCF中采用两种dropout技术:message dropout和node dropout。message dropout:随机丢弃传出的消息(outgoing message)。具体而言,我们以概率refine representation。node dropout:随机阻塞一个节点并丢弃该节点传出的所有消息。对于第dropout ratio。
注意,
dropout仅用于训练并且必须在测试期间禁用。message dropout使得representaion对于user-item之间单个连接具有更强的鲁棒性,而node dropout则侧重于减少特定用户或特定item的影响。我们在实验中研究message dropout和node dropout对于NGCF的影响。
1.1.5 讨论
这里我们首先展示
NGCF如何推广SVD++,然后我们分析NGCF的时间复杂度。NGCF和SVD++:SVD++可以看做是没有高阶传播层的NGCF的特例。具体而言,我们将
1。在传播层中,我们禁用了转换矩阵和非线性激活函数。然后,itemrepresentation。我们把这个简化模型称作NGCF-SVD,它可以表述为:显然,通过分别设置
SVD++模型。此外,另一个广泛使用的
item-based CF模型FISM也可以被视为NGCF的特例,其中上式中时间复杂度:我们可以看到,逐层(
layer-wise)传播规则是主要的操作。对于第
对于预测层只涉及内积,它的时间复杂度为
因此,
NGCF的整体复杂度为MF和NGCF在Gowalla数据集上的训练成本分别为20秒左右和80秒左右,在推断期间MF和NGCF的时间成本分别为80秒和260秒。
1.2 实验
我们在真实世界的三个数据集上进行实验,从而评估我们提出的方法,尤其是
embedding传播层。我们旨在回答以下研究问题:RQ1:和SOTA的CF方法相比,NGCF的表现如何?RQ2:不同的超参数setting(如,层的深度、embedding传播层、layer-aggregation机制、message dropout、node dropout)如何影响NGCF?RQ3:如何从高阶连通性中受益?
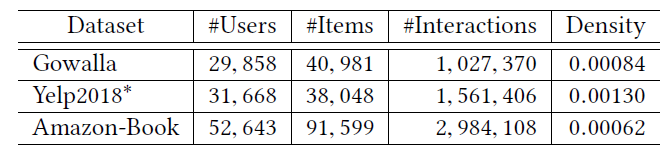
数据集:我们选择三个
benchmark数据集Gowalla、Yelp2018、Amazon-book。这些数据集可公开访问,并且在领域、规模、稀疏性等方面各不相同。Gowalla数据集:这是从Gowalla获得的check-in数据集,用户通过checking-in来共享他们的位置(location)。为了确保数据集的质量,我们使用10-core setting,即保留至少有十次交互的用户和item。Yelp2018:来自2018年的Yelp挑战赛的数据集,其中餐馆、酒吧等当地企业被视为item。为了确保数据质量,我们也使用10-core setting。Amazon-book:Amazon-review是一个广泛使用的产品推荐数据集,这里我们从中选择了Amazon-book。同样地,我们使用10-core setting来确保每个用户和每个item至少有十次交互。
对于每个数据集,我们随机选择每个用户
80%的历史交互构成训练集,其余的20%历史交互作为测试集。在训练集中,我们随机选择10%的交互作为验证集来调整超参数。对于每个观察到的
user-item交互,我们将其视为一个正样本,然后进行负采样策略:将用户和历史没有互动的负item构建pair对。这些数据集的统计信息如下表所示。
评估指标:对于测试集中的每个用户,我们将用户未交互的所有
item视为负item。然后每个方法输出用户对所有item(除了训练集中的正item)的偏好分。为了评估top-K推荐和偏好排序(preference ranking),我们采用了两种广泛使用的评估指标:recall@K和ndcg@K,默认情况下K=20。我们报告测试集中所有用户的平均指标。baseline方法:为了证明有效性,我们将NGCF方法和以下方法进行比较:MF:这是通过贝叶斯个性化排名(Bayesian personalized ranking: BPR)损失函数优化的矩阵分解方法,它仅利用user-item直接交互作为交互函数的目标值(target value)。NeuMF:这是SOTA的神经网络协同过滤模型。该方法拼接user embedding和item embedding,然后使用多个隐层从而捕获用户和item的非线性特征交互。具体而言,我们采用两层的普通架构,其中每个隐层的维度保持不变。CMN:这是SOTA的memory-based模型,其中user representation通过memory layer有意地组合相邻用户的memory slot。注意,一阶连接用于查找和相同item交互的相似用户。HOP-Rec:这是一个SOTA的graph-based模型。该方法利用从随机游走得到的高阶邻居来丰富user-item交互数据。PinSage:该方法在item-item graph上应用GraphSAGE。在这里,我们将该方法应用于user-item交互图。具体而言,我们采用了两层图卷积层,并且隐层维度设为embedding size。GC-MC:该模型采用GCN encoder来生成user representations和item representation,其中仅考虑一阶邻居。具体而言,我们使用一层图卷积层,并且隐层维度设为embedding size。
我们也尝试了
Spectral CF,但是发现特征分解导致很高的时间成本和资源成本,尤其是当用户数量和item数量很大时。因此,尽管该方法在小数据集上取得了不错的性能,但是我们没有选择和它进行比较。为了公平地比较,所有方法都优化了
BPR loss。参数配置:我们在
Tensorflow中实现了我们的NGCF模型。所有模型的
embedding size固定为64。对于
HOP-Rec,我们选择随机游走step的调优集合为{1,2,3},学习率的调优集合为{0.025, 0.020, 0.015, 0.010}。我们使用
Adam优化器优化除了HOP-Rec之外的所有模型,其中batch size固定为1024。在超参数方面,我们对超参数应用网格搜索:学习率搜索范围
{0.0001, 0.0005, 0.001, 0.005}、L2正则化系数搜索范围dropout ratio搜索范围{0.0, 0.1, ... , 0.8}。此外,我们对
GC-MC和NGCF应用node dropout技术,其中dropout ratio搜索范围为{0.0, 0.1, ... , 0.8}。我们使用
Xavier初始化器来初始化模型参数。我们执行早停策略:如果在连续
50个epoch中,验证集的recall@20指标没有提升,则提前停止训练。为了建模三阶连通性,我们将
NGCF L的深度设置为3。在没有特殊说明的情况下,我们给出了三层embedding传播层的结果,node dropout ratio = 0.0、message dropout ratio = 0.1。
1.2.1 RQ1 性能比较
我们从比较所有方法的性能开始,然后探索高阶连通性建模如何提升稀疏环境下的性能。
下表报告了所有方法性能比较的结果。可以看到:
MF在三个数据集上的表现不佳。这表明内积不足以捕获用户和item之间的复杂关系,从而限制了模型性能。NeuMF在所有情况下始终优于MF,证明了user embedding和item embedding之间非线性特征交互的重要性。然而,
MF和NeuMF都没有显式地对embedding学习过程中的连通性进行建模,这很容易导致次优suboptimal的representation。与
MF和NeuMF相比,GC-MC的性能验证了融合一阶邻居可以改善representation learning。然而,在
Gowalla中,GC-MC在ndcg@20指标行不如NeuMF。原因可能是GC-MC未能充分探索用户和item之间的非线性特征交互。大多数情况下,
CMN通常比GC-MC得到更好的性能。这种改进可能归因于神经注意力机制(neural attention mechanism),它可以指定每个相邻用户的注意力权重,而不是GC-MC中使用的相同权重、或者启发式权重。PinSage在Gowalla和Amazon-Book中的表现略逊于CMN,但是在Yelp2018中的表现要好得多。同时HOP-Rec在大多数情况下总体上取得了显著的提升。这是讲得通的,因为
PinSage在embedding函数中引入了高阶连通性,HOP-Rec利用高阶邻居来丰富训练数据,而CMN只考虑相似的用户。因此,这表明了对高阶连通性或高阶邻居建模的积极影响。NGCF始终在所有数据集上产生最佳性能。具体而言,NGCF在Gowalla、Yelp2018、Amazon-Book数据集中在recall@20方面比最强baseline分别提高了11.68%、11.97%、9.61%。通过堆叠多个
embedding传播层,NGCF能够显式探索高阶连通性,而CMN和GC-MC仅利用一阶邻居来指导representation learning。这验证了在embedding函数中捕获协同信号的重要性。此外,和
PinSage相比,NGCF考虑多粒度表示(multi-grained representation)来推断用户偏好,而PinSage仅使用最后一层的输出。这表明不同的传播层在representation中编码不同的信息。并且,对
HOP-Rec的改进表明embedding函数中的显式编码CF可以获得更好的representation。HOP-Rec效果也不错,而且计算复杂度不高、简单易于实现。
我们进行
one-sample的t-test,p-value < 0.05表明NGCF对最强baseline(下划线标明)的改进在统计上是显著的。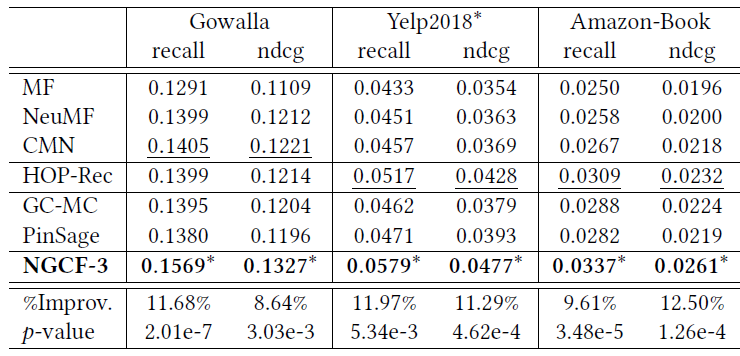
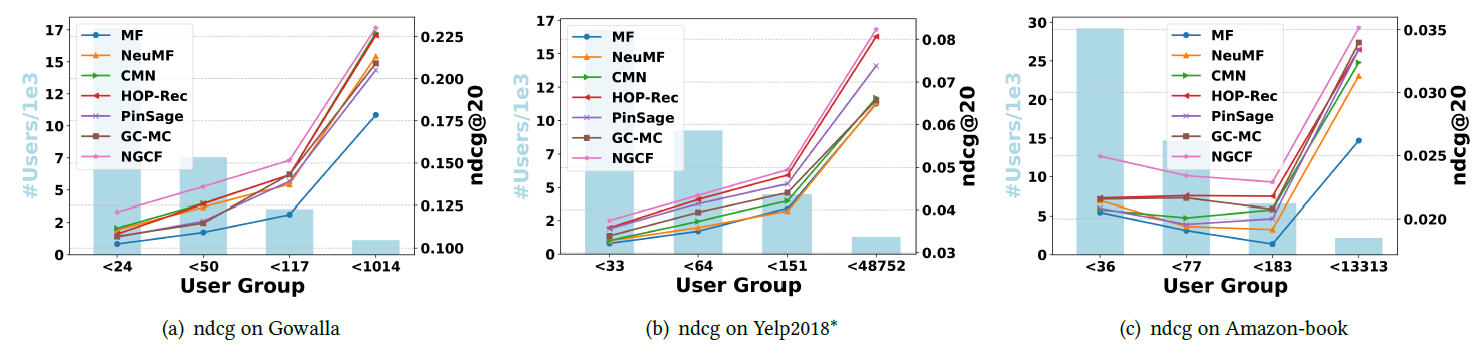
稀疏性问题通常限制了推荐系统的表达能力,因为不活跃用户的少量交互不足以生成高质量的
representation。我们考察利用连通性信息(connectivity information)是否有助于缓解稀疏性问题。为此,我们对不同稀疏性水平的用户组(user group)进行了实验。具体而言,基于每个用户的交互次数,我们将测试集分为四组,每组的用户具有相同的交互次数。以
Gowalla数据集为例,每个用户的交互次数分别小于24、50、117、1014。下图展示了
Gowalla、Yelp 2018、Amazon-Book数据集的不同用户组中关于ndcg@20的结果。背景的直方图表示每个分组中的用户量,曲线表示ndcg@20指标。我们在recall@20方面看到了类似的性能趋势,但是由于空间限制而省略了该部分。可以看到:
NGCF和HOP-Rec始终优于所有用户组的所有其它baseline。这表明利用高阶连通性可以极大地促进非活跃用户的representation learning,因为可以有效地捕获协同信号。因此,解决推荐系统中的稀疏性问题可能是有希望的,我们将其留待未来的工作中。联合分析图
(a),(b),(c),我们观察到前两组取得的提升(例如,在Gowalla数据集中NGCF对于< 24和< 50的最佳baseline上分别提高了8.49%和7.79%)比其它组更为显著(例如,在Gowalla数据集中NGCF对于< 1014的最佳baseline提高了1.29%)。这验证了embedding传播有利于相对不活跃的用户。
1.2.2 RQ2 NGCF 研究
由于
embedding传播层在NGCF中起着举足轻重的作用,因此我们研究了它对于性能的影响。我们首先探索层数的影响,然后我们研究拉普拉斯矩阵(即用户
item此外,我们分析了关键因素的影响,例如
node dropout和message dropout。最后,我们还研究了
NGCF的训练过程。
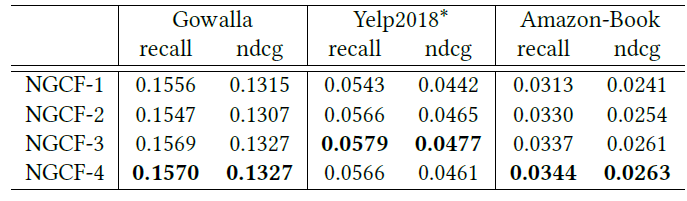
层数的影响:为了研究
NGCF是否可以从多个embedding传播层中受益,我们改变了模型深度。具体而言,我们探索了层数为{1,2,3,4}。下表给出了实验结果,其中NGCF-3表示具有三层embedding传播层的模型,其它符号类似。联合下表和上表(所有方法性能比较结果表)可以看到:增加
NGCF的深度可以大大提升推荐效果。显然,NGCF-2和NGCF-3在所有方面都比NGCF-1实现了一致的提升,因为NGCF-1仅考虑了一阶邻居。我们将所有提升归因于
CF效应的有效建模:协同用户相似性(collaborative user similarity)和协同信号(collaborative signal)分别由二阶连通性和三阶连通性承载(carried)。当在
NGCF-3之后进一步堆叠传播层时,我们发现NGCF-4在Yelp 2018数据集上过拟合。这可能是因为太深的架构会给representation learning带来噪音。而其它两个数据集上的边际提升证明了三层传播层足以捕获
CF信号。当传播层数变化时,
NGCF在三个数据集上始终优于其它方法。这再次验证了NGCF的有效性,从而表明显式建模高阶连通性可以极大地促进推荐任务。
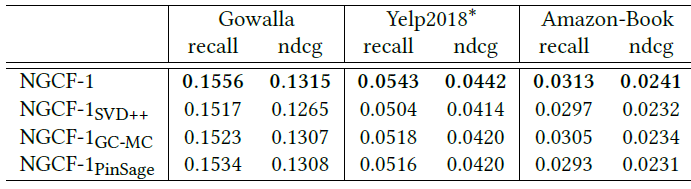
embedding传播层的效果和Layer-Aggregation机制:为了研究embedding传播层(即图卷积层)如何影响性能,我们考虑了使用使用不同layer的NGCF-1变体。具体而言,我们从消息传递函数中删除了节点及其邻居之间的
representation交互,并将其设置为PinSage和GC-MC的representation交互,分别称为对于
其中
对于
其中:
此外,基于
NGCF-SVD,我们得到NGCF的关于SVD++的变体,称作我们在下表中显示了实验结果,并且可以发现:
NGCF-1始终优于所有变体。我们将改进归因于representation交互(即affinity以及注意力机制等等函数。同时,所有变体仅考虑线性变换。因此,这验证了我们
embedding传播函数的合理性和有效性。在大多数情况下,
item到用户的消息传递、只有用户到item的消息传递)和非线性变换的重要性。联合下表和上表(所有方法性能比较结果表)可以看到:当将所有层的输出拼接在一起时,
PinSage和GC-MC获得更好的性能。这表明layer-aggregation机制的重要性。
dropout效果:遵从GC-MC的工作,我们采用了node dropout和message dropout技术来防止NGCF过拟合。下图给出了message dropout ratenode dropout rate在两种
dropout策略之间,node dropout提供了更好的性能。以Gowalla为例,设置recall@20(0.1514),这优于message dropout得到最好的recall@20(0.1506) 。一个可能的原因是:丢弃来自特定用户和特定
item的所有outgoing message使得representation不仅可以抵抗特定边的影响,还可以抵抗节点的影响。因此,node dropout比message dropout更有效,这和GC-MC工作的发现相一致。我们认为这是一个有趣的发现,这意味着
node dropout可以成为解决图神经网络过拟合的有效策略。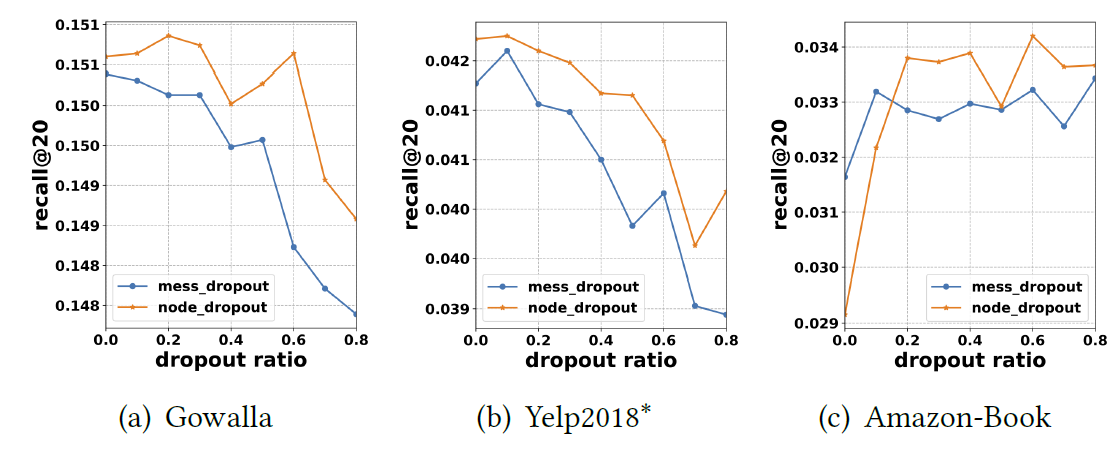
Epoch对测试性能影响:下图给出了MF和NGCF在每个epoch的测试性能(recall@20)。由于空间限制,我们省略了ndcg@20指标,因为该指标的性能趋势和recall@20是类似的。可以看到:
NGCF在三个数据集上表现出比MF更快的收敛速度。这是合理的,因为在
mini-batch中优化交互pair对时,涉及间接相连的用户和item。这样的观察证明了NGCF具有更好的模型容量,以及在embedding空间中执行embedding传播的有效性。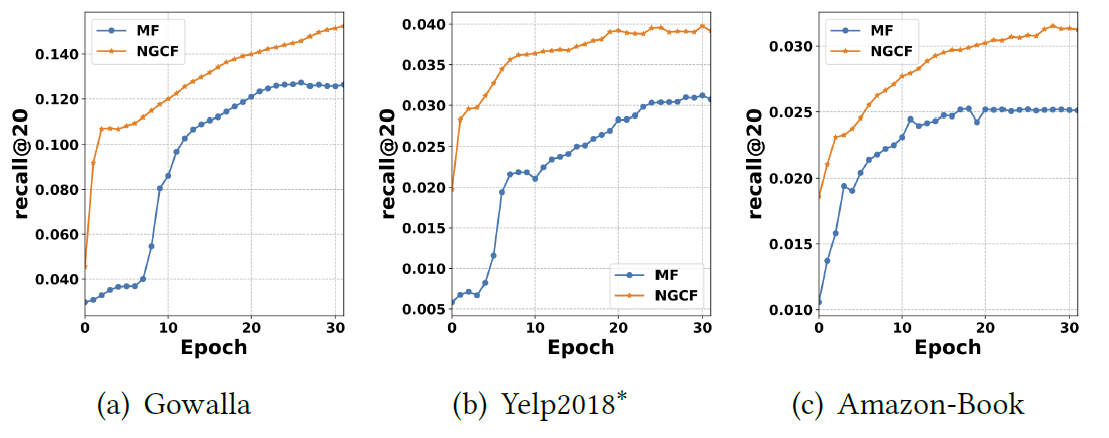
1.2.3 RQ3 高阶连通性的效果
这里我们试图了解
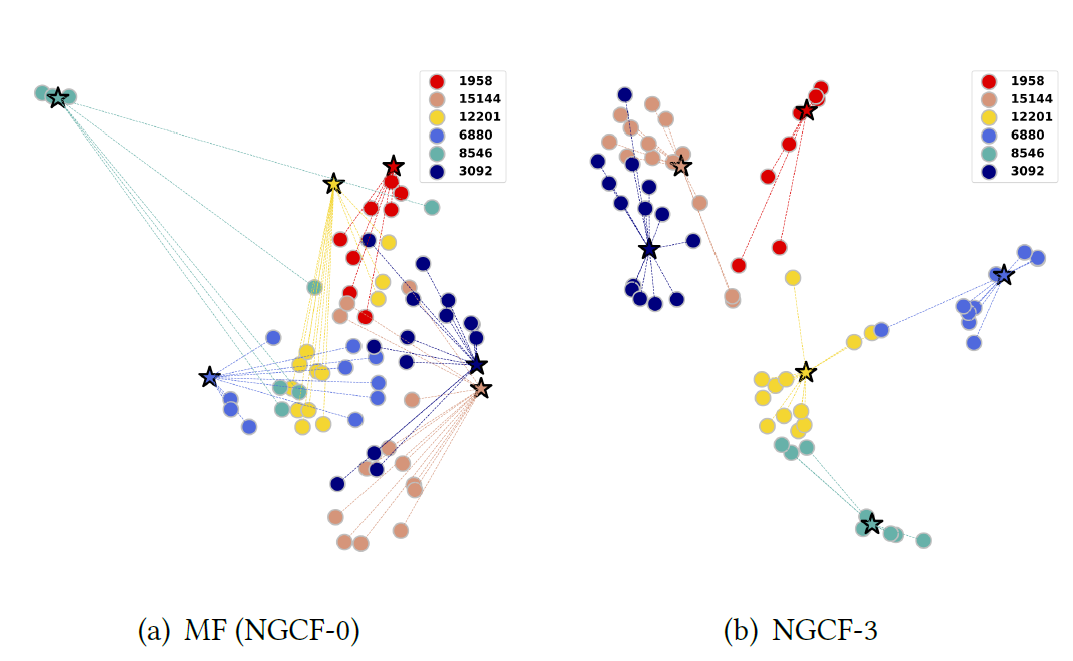
embedding传播层如何促进embedding空间中的representation learning。为此,我们从Gowalla数据集中随机选择了6个用户及其相关的item。我们观察他们的representation如何受到NGCF深度的影响。下图
(a)和(b)分别显示了来自MF(即NGCF-0)和NGCF-3的representation的可视化(通过t-SNE)。每个星星代表Gowalla数据集中的一个用户,和星星相同颜色的点代表相关的item。注意,这些
item来自测试集,并且这些item和用户构成的pair对不会出现在训练过程中。可以看到:
用户和
item的连通性很好地反映在embedding空间中,即它们嵌入到空间中相近的位置。具体而言,
NGCF-3的representation表现出可识别的聚类,这意味着具有相同颜色的点(即相同用户消费的item)倾向于形成聚类。联合分析图
(a)和图(b)中的相同用户(例如12201黄色星星和6880蓝色星星),我们发现:当堆叠三层embedding传播层时,他们历史item的embedding往往更加靠近。这定性地验证了所提出的embedding传播层能够将显式的协同信号(通过NGCF-3)注入到representation中。
将来的工作:
结合注意力机制进一步改进
NGCF,从而在embedding传播过程中学习邻居的可变权重,以及不同阶连接性的可变权重。这将有利于模型的泛化和可解释性。探索关于
user/item embedding和图结构的对抗学习,从而增强NGCF的鲁棒性。这项工作代表了在基于模型的CF中利用消息传递机制开发结构知识的初步尝试,并开辟了新的研究可能性。